
CONTENTS

USA
Thank you for reaching out to Sigma Software!
Please fill the form below. Our team will contact you shortly.
Sigma Software has offices in multiple locations in Europe, Northern America, Asia, and Latin America.
USA

Sweden

Germany

Canada

Israel

Singapore

UAE

Australia

Austria

Ukraine

Poland

Argentina

Brazil

Bulgaria

Colombia

Czech Republic

Mexico

Portugal

Romania

Uzbekistan
10 min read
Data is everywhere, yet its payoff isn't always there. Many IT leaders struggle with scattered analytics, rising storage costs, and unclear returns. We faced the same hurdles: we had data, we had tools, but the value was hard to pin down. So, we used operations within our Data CoE as a testing ground. By applying a Customer Zero strategy inside our organization, we built capabilities that now serve both us and our clients. The key? We stopped chasing technology and started defining a purpose. This article shares some details of our journey, insights we gained along the way, and practical tips on how to get things done better from the very start.
Sigma Software’s Data Center of Excellence (CoE) was launched over 15 years ago and built on the same principles that shaped our AI, Information Security, and other CoEs over the past two decades – the strategy many now associate with the “Customer Zero” concept. At its core, it means that any product, capability, or service intended for clients must be adopted internally and prove valuable to our own teams first.

Thus, we relied on the Data CoE Business Intelligence capability to collect, monitor, and analyze data on our operations, supporting both day-to-day and strategic decisions with clear, data-driven insights. Those insights depend on high-quality data in the first place, and that’s where we ran into the same obstacles many companies face today. The IT department, typically responsible for early-stage data governance, identifies challenges that are not always easy to turn into opportunities:
Further, we’ll walk you through the practices that helped us overcome these challenges, turning internal capabilities into services now used by our clients. These insights are especially relevant for Heads of IT, CIOs, and COOs looking to shift data from a cost center to a source of business value.
People generally dislike building business cases within the internal IT. It’s hard to convince anyone that moving from Excel to a structured data storage and online analytics tools is worth the investment. How do you justify such an investment when it might take a team of costly engineers working full-time for six months just to get the analytics up and running?
To be completely honest, our first data analytics platform, which was a foundation for data products and business cases, as well as the investment behind it, wasn’t a complete success. It was fully rewritten within five years of the initial pilot because it simply could not scale and adapt to the changing needs of the fast-growing organization. However, the product we launched proved value to the stakeholders, which was the key outcome.
Looking back, some unexpected elements from those early pilots turned out to be even more valuable than the outcome itself:
“At the end of the day, the technical platform can always be rebuilt. What really matters is educating and aligning people around value, commitment, and credibility. Right from the start” – emphasizes Anatoliy Kochetov, COO at Sigma Software – “this is a key foundation and the best investment you can make early”.
Our early business cases focused on cost optimization. One of the first successful data products we built involved tracking office space utilization to identify savings opportunities well ahead of the lease renewals. Even with static data, the initiative delivered at least $200K in annual savings.
While the savings forecast was promising and the business value clear, it was still critical to ensure that collecting and processing this data wouldn’t cost twice as much as it saved. That’s why we applied two key principles for our data products development:
Even though PoC became more or less a buzzword in the world of data and especially AI, it didn’t lose its true sense and actuality. We piloted different approaches, but the one that worked best for us at the early stages was focusing on building PoCs on top of open-source tools and affordable commercial solutions. This allowed us to validate concepts quickly without committing to heavy investments.
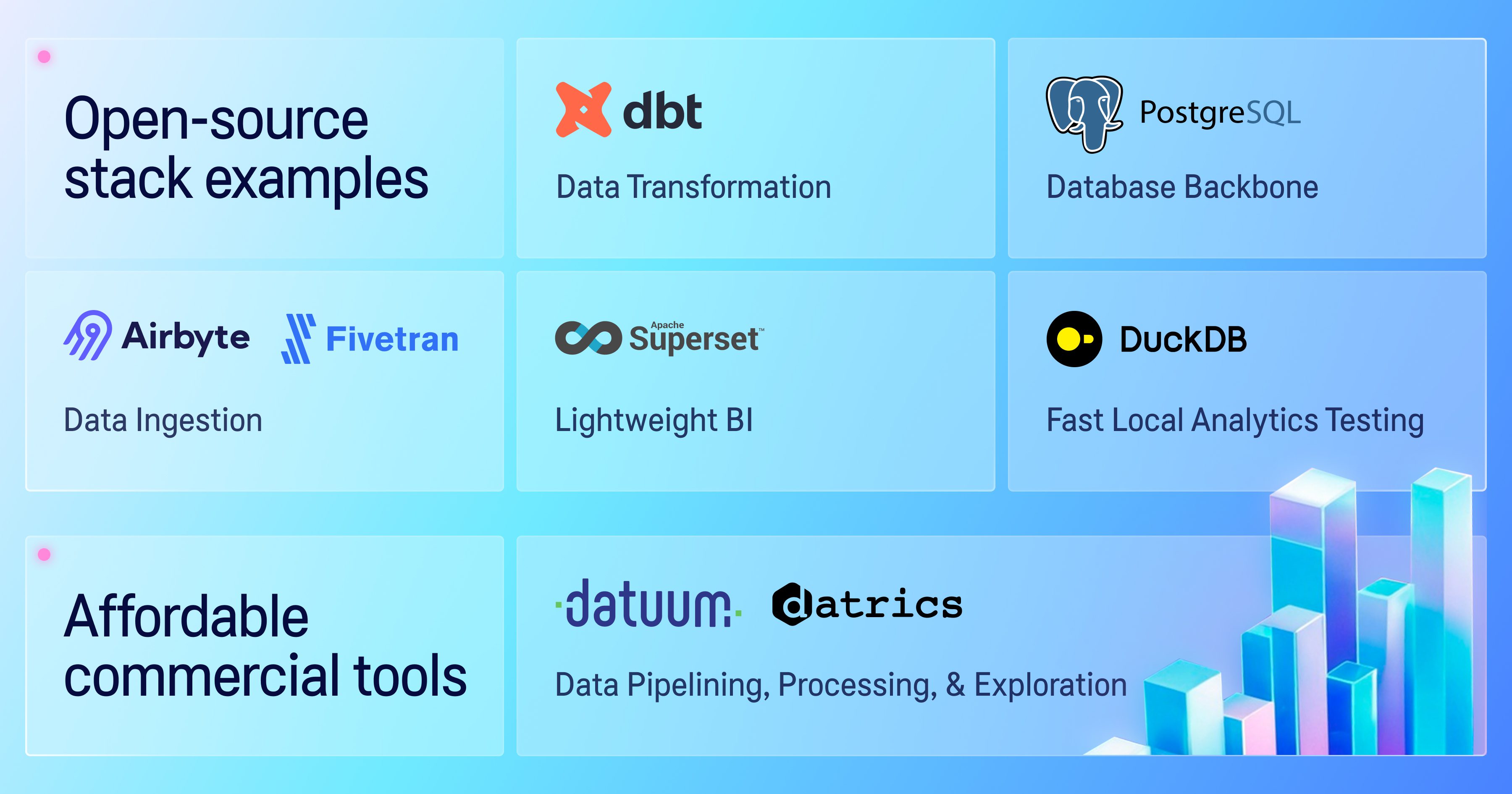
We didn’t apply design thinking in our early attempts at building a data platform and products. We focused too much on technology and tools, going all the way from creating a dedicated data warehouse to purchasing commercial analytics tools. Many of the solutions were implemented simply because they were considered state-of-the-art, had worked elsewhere, or came recommended by well-known consultants. And, perhaps, they worked to some extent for that time. The only problem was that we were looking for the right tools without fully shaping the concept behind why we actually needed them.
The key takeaway is that design thinking applies to most, if not all, aspects of Data Platform and new Data Product design, and it inevitably pays off with better product fit and fewer re-dos.
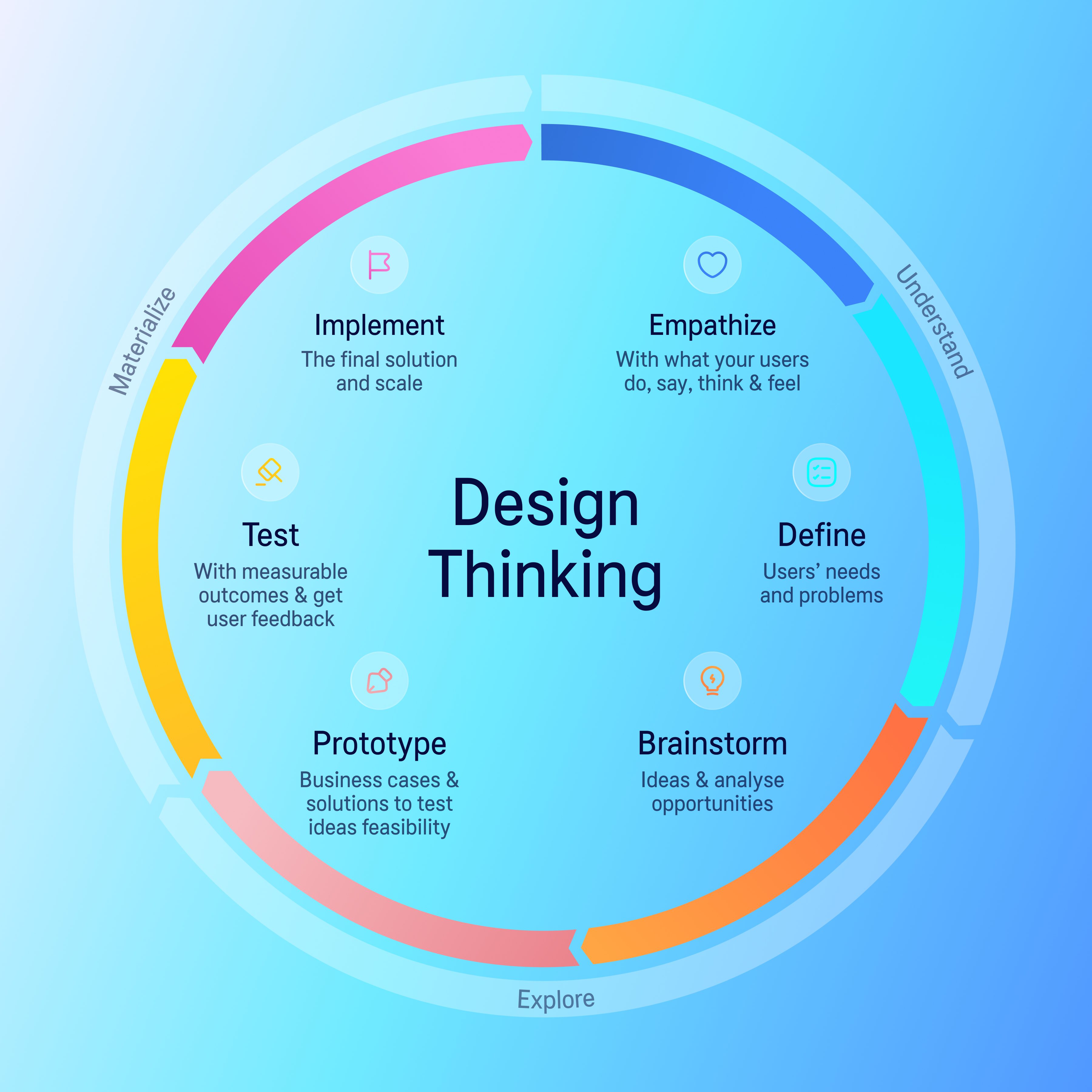
The next time around, we applied design thinking from the start, shaping a new approach we’ve relied on ever since:
A well-structured data model is the backbone of any scalable data platform you would need to have in place for building your data products successfully. Start by breaking it down into sub-domains, validate each with the stakeholders, and iterate domain by domain. This also lays the groundwork for cleaner data pipelines and more meaningful analytics.
Data should reflect how the organization works today or will work tomorrow, not how it worked years ago. Revisit the process layer before locking in your data structures. When needed, go back to the ideation phase of the Design Thinking cycle.
Don’t theorize – prototype. Try out different architectural patterns: Data Warehouse, Data Lakehouse, or hybrid architectures like Data Fabric.
Ask yourself: Do you need data marts or a semantic layer? Should your platform support APIs, reverse ETL, or direct-to-app analytics?
Here’s how Stas Samko, who leads our Data CoE, reflects on it: “When building a modern data platform, technical tooling is only a part of the picture. You need lean experimentation, strong process understanding, and a design-led approach to ensure the platform delivers real, measurable value. Start small, iterate fast, and design with people, not just infrastructure in mind.”
Once your initial business cases show results, the foundational architecture is in place, and a core data budget is secured, the next critical question is: how do you ensure time and money are spent wisely, with the maximum return on investment?
Here are several best practices we found valuable at this stage:
1. Focus on Data Product Management
As your data initiatives scale, don’t expect business units to independently define the use cases or build data models. You need a dedicated team of Data Product Managers – ideally within your IT or Data organization. These professionals bridge the gap between data engineering and business domains. They drive alignment, surface real needs, and turn ideas into successful data products. Their domain expertise and stakeholder engagement are critical to unlocking the high-impact use cases. Many people we engage pass our Product Management trainings, so it is not always mandatory to rely on extremely experienced staff only.
2. Adopt Lean Data Governance
You don’t need a complex, multi-layered data governance structure to get started. Begin lean: assign a Data Architect, ideally someone who also understands and maintains the corporate data model. Yes, this creates a temporary bus factor risk, but it’s essential to set the foundation. This person becomes your internal compass, guiding data quality, structure, and reuse. You can build broader governance frameworks as your data maturity grows.
3. Introduce Internal Billing for Data Products
One way to drive accountability and perceived value is through internal billing models. When departments are “charged” for the data products set-up and use, they treat them with more consideration, just like any external service. This model helps justify future funding, reinforce product value, and make data products ROI more visible. This also brings more discipline to the data services provision processes – people simply won’t pay for poor quality or zero impact.
4. Explore External Data Marketplaces
Not all data must remain internal. If you have datasets that don’t expose sensitive IP or commercial secrets, consider monetizing them externally. Numerous data marketplaces allow you to list datasets that can be accessed and purchased through APIs. This can create an additional revenue stream to fund further IT or data investments, while positioning your company in the data economy.
5. Enable Self-Service Analytics
Your best-built data products should be the flagship examples. Though you can’t build everything for everyone. Empower your users with self-service BI capabilities. Establish well-designed Data Marts and implement a permission-based access layer, where access is automatically controlled based on roles or departments. This creates a balance between flexibility and governance, and unleashes analytical potential across your organization.
6. Engage Hyperscalers for Co-Financing
If you’re using cloud infrastructure, don’t overlook funding opportunities from hyperscalers like Microsoft (Azure ECIF), Amazon (AWS MAP), or Google Cloud. These companies often co-finance up to 50% of your project costs if you commit to using their services and work with approved partners. These programs can dramatically improve your cloud ROI and support larger-scale data platform rollouts.
At Sigma Software, we believe in the Customer Zero strategy – testing and refining every data capability internally before offering it to clients. Now, after more than 15 years of Data CoE evolution, our internal best practice has become our professional offering, which we share here.
Key Best Practices from Sigma Software’s Data Excellence:
Through this approach, we have transformed internal innovation into real-world data solutions that reduce costs, generate revenue, and unlock business insights – helping our clients turn their data from a cost center into a scalable model that powers competitive advantage.

Anatoliy Kochetov joined Sigma Software in 2008 as a Project Manager, building his path toward Delivery Director in 2017 and Chief Operations Officer in early 2025. Throughout his career, Anatoliy has been deeply involved in complex projects with enterprise clients from diverse domains, helping them innovate and navigate global challenges.


A Software Bill of Materials (SBOM) is becoming one of the most important documents in modern software development. Still, many organizations struggle to create...

As cloud sovereignty becomes a strategic priority across the EU, Sigma Software applies its deep expertise and extensive experience to contribute to the develop...

Oleksandr Plyska, Vice President at Sigma Software, leads a global business unit specializing in several industries, including aviation. The unit’s capabilities...