
CONTENTS
Maturity of Big Data technologies
Thank you for reaching out to Sigma Software!
Please fill the form below. Our team will contact you shortly.
Sigma Software has offices in multiple locations in Europe, Northern America, Asia, and Latin America.

USA

Sweden

Germany

Canada

Israel

Singapore

UAE

Australia

Austria

Ukraine

Poland

Argentina

Brazil

Bulgaria

Colombia

Czech Republic

Mexico

Portugal

Romania

Uzbekistan
7 min read
Below you can find the article of our colleague and Big Data expert Boris Trofimov. The article was published on ITProPortal.
One of the biggest myths still remains that only big companies can afford Big Data driven solutions, it is appropriate for massive data volumes only and is expensive as a fortune. That is no longer true, and there were several revolutions that changed this state of mind.
The first revolution is related to maturity and quality. There is no secret that ten years ago big data technologies required certain efforts to make it work or make all pieces work together.
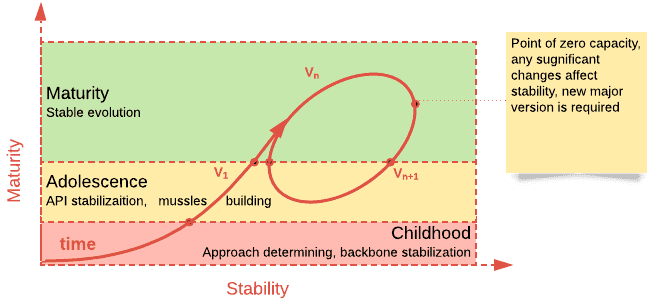
Picture 1. Typical stages, growing technologies pass-through
There were countless stories in the past coming from developers who wasted 80% of time trying to overcome silly glitches with Spark, Hadoop, Kafka or others. Nowadays these technologies became sufficiently reliable, they eliminated childhood diseases and learned how to work with each other.
There is a much bigger chance to see infrastructure outages than catch internal bugs. Even infrastructure issues can be tolerated in most cases gently as most big data processing frameworks are designed to be fault-tolerant. In addition, those technologies provide stable, powerful and simple abstractions over calculations and allow developers to be focused on the business side of development.
The second revolution is happening right now — myriads of open source and proprietary technologies have been invented these years — Apache Pino, Delta Lake, Hudi, Presto, Clickhouse, Snowflake, Upsolver, Serverless and more and more. Creative energy and ideas of thousands of developers have been converted into bold and outstanding solutions with a great motivating synergy around.
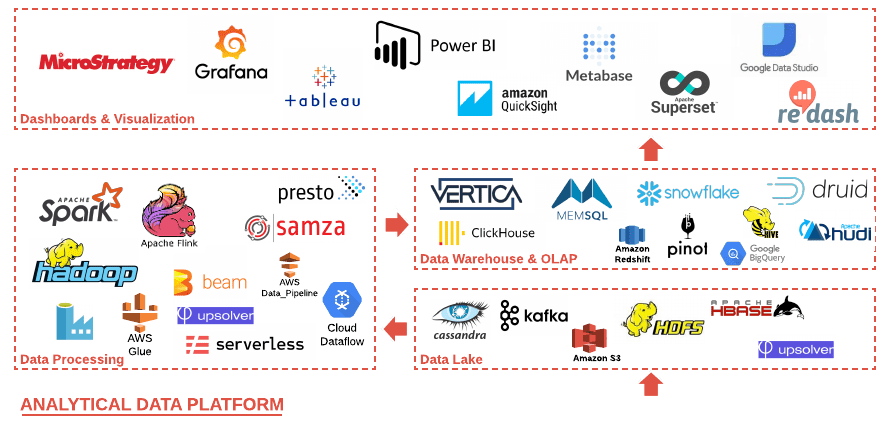
Picture 2. Big Data technology stack
Let’s address a typical analytical data platform (ADP). It consists of four major tiers:
Every tier has sufficient alternatives for any taste and requirement. Half of those technologies appeared within the last 5 years.
The important thing about them is that technologies are developed with the intention to be compatible with each other. For instance, typical low-cost small ADP might consist of Apache Spark as a base of processing components, AWS S3 or similar as a Data Lake, Clickhouse as a Warehouse and OLAP for low latency queries and Grafana for nice dashboarding (see Pic. 3).
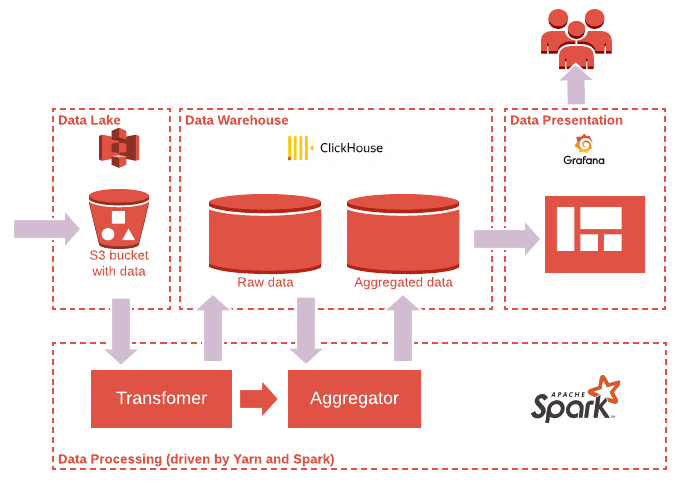
Picture 3. Typical low-cost small ADP
More complex ADPs with stronger guarantees could be composed in a different way. For instance, introducing Apache Hudi with S3 as a Data Warehouse can ensure a much bigger scale while Clickhouse remains for low-latency access to aggregated data (see Pic. 4).
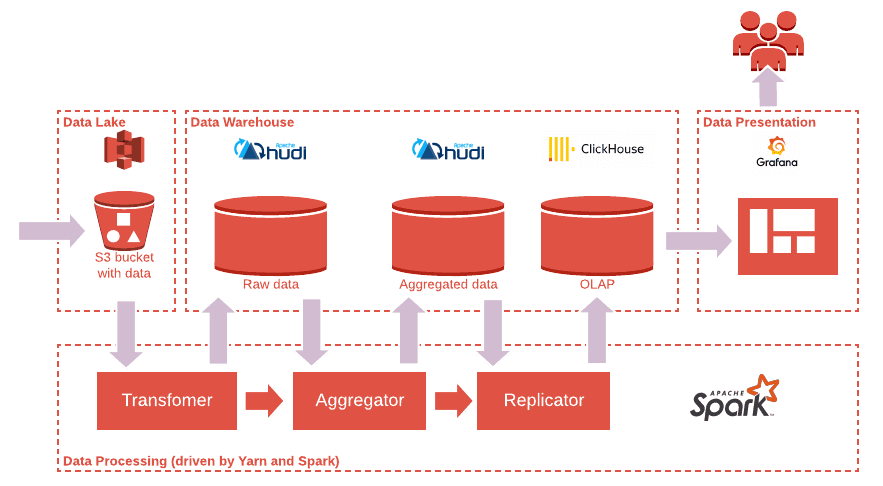
Picture 4. ADP on a bigger scale with stronger guarantees
The third revolution is made by clouds. Cloud services became real game changers. They address Big Data as a ready-to-use platform (Big Data as a Service) allowing developers to focus on feature development, letting cloud care about infrastructure.
Picture 5 shows another example of ADP which leverages the power of serverless technologies from storage, processing till presentation tier. It has the same design ideas while technologies are replaced by AWS managed services.
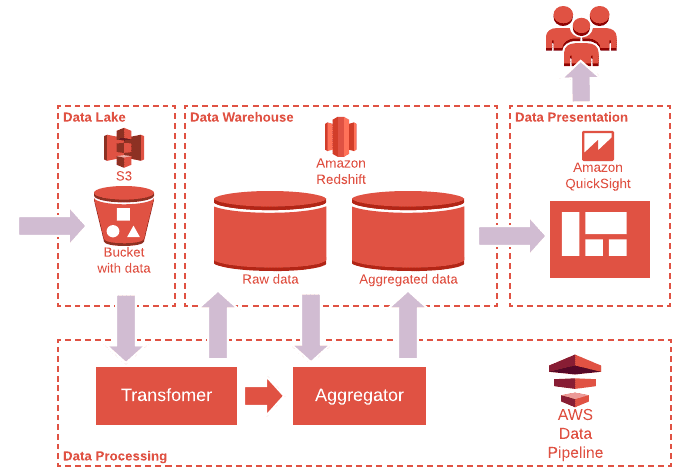
Picture 5. Typical low-cost serverless ADP
Worth saying that the AWS here is just an example, the same ADP could be built on top of any other cloud provider.
Developers have an option to choose particular technologies and a degree of serverless. More serverless it is, more composable it could be, however more vendor-locked it becomes as a down side. Solutions being locked on a particular cloud provider and serverless stack can have a quick time to market runway. Wise choice between serverless technologies can make the solution cost effective.
This option though is not quite useful for startups as they tend to leverage typical $100K cloud credits and jumpings between AWS, GCP and Azure is quite an ordinary lifestyle. This fact has to be clarified in advance and more cloud-agnostic technologies have to be proposed instead.
Usually, engineers distinguish the following costs:
Let’s address them one by one.
Cloud technologies definitely simplify engineering efforts. There are several zones where it has a positive impact.
The first one is architecture and design decisions. Serverless stack provides a rich set of patterns and reusable components which gives a solid and consistent foundation for solution’s architecture.
There is only one concern that might slow down the design stage — big data technologies are distributed by nature so related solutions must be designed with thought about possible failures and outages to be able to ensure data availability and consistency. As a bonus, solutions require less efforts to be scaled out.
The second one is integration and end-to-end testing. Serverless stack allows creating isolated sandboxes, play, test, fix issues, therefore reducing development loopback and time.
Another advantage is that cloud imposes automation of the solution’s deployment process. Needless to say this feature is a mandatory attribute of any successful team.
One of the major goals that cloud providers claim to solve was less effort to monitor and keep production environments alive. They tried to build some kind of ideal abstraction with almost zero devops involvement.
The reality is a bit different though. With respect to that idea, usually maintenance still requires some efforts. The table below highlights the most prominent kinds.
| Efforts | Frequency | Impact |
| Mitigate software bugs | Depends on particular cloud and service, usually it is low. | Most typical issue is connected to computational outages. Example: Yarn cluster got stuck and does not accept any jobs. Typical solution: relocate the application asap to another cloned cluster; once issue is mitigated, contact to support. |
| Mitigate infrastructure outages | low | The most typical issue is connected to accidental computational and access outages. Usually they are recoverable and do not exceed declared SLA. Example: Object Storage rejects all read operations. Typical solution: affected application does multiple attempts to rerun jobs without any intervention, as a fallback the application stops processing till the issue is resolved by the cloud provider. |
| Regular maintenance activities like scaling, upgrades etc. | low-high Depends on the engineering team. | Cloud providers usually take care of vital things like security patches, while ordinary upgrade is on engineer’s shoulders. Impact can be reduced dramatically if engineering teams leverage Infrastructure As Code (IAC) tools, automate deployments and enable autoscaling in advance. |
But beside it, the bill depends a lot on infrastructure and license costs. Design phase is extremely important as it gives a chance to challenge particular technologies and estimate its runtime costs in advance.
Another important side of big data technologies that concerns customers — cost of change. Our experience shows there is no difference between Big Data and any other technologies. If the solution is not over-engineered then the cost of change is completely comparable to a non-big-data stack. There is one benefit though that comes with Big Data. It is natural for Big Data solutions to be designed as decoupled. Properly designed solutions do not look like monolith, allowing to apply local changes within short terms where it is needed and with less risk to affect production.
As a summary, we do think Big Data can be affordable. It proposes new design patterns and approaches to developers, who can leverage it to assemble any analytical data platform respecting strongest business requirements and be cost-effective at the same time.
Big Data driven solutions might be a great foundation for fast-growing startups who would like to be flexible, apply quick changes and have short TTM runway. Once businesses demand bigger data volumes, Big Data driven solutions might scale alongside with business.
Big Data technologies allow implementing near-real-time analytics on small or big scale while classic solutions struggle with performance.
Cloud providers have elevated Big Data on the next level providing reliable, scalable and ready-to-use capabilities. It’s never been easier to develop cost-effective ADPs with quick delivery. Elevate your business with Big Data.

Boris Trofimov, a Software Architect with 15 years of experience in software development, architecting, team leading, and educating. Throughout years, he has successfully participated in tons of projects shaping Big Data architecture for companies in diverse industries. His portfolio goes from creating cost-efficient Big Data solutions for innovative startups & getting them delivered in 2 weeks to design of advertisement data platform for the owner of the largest advertising and video platforms with millions of users and billions of video plays. The platform that was developed by Sigma Software team was capable to process 120TB data every day on 2.5M events processed per second.


The shift from fee-for-service to value-based care changes the math for medical organizations. You only get paid when patients stay healthy and avoid unnecessar...

Legacy systems send a chill down the spine of every developer, manager, and director. Everyone knows change is needed, and everyone knows change is hard. Refact...

Once organizations adopt SBOMs, the next step is to roll them out across the teams. This is when the initiatives tend to slow down. In many cases, the challenge...