




















Almost every year we increase the number of CPU cores in our devices to increase overall performance and user experience. Having an eight-core phone is not a big deal nowadays. Although there exists another kind of programmable unit that is usually ignored by most of the programmers. It has a multitude of computing cores, hundreds of them, and it is a GPU or graphics processing unit responsible for drawing the user interface and handling 3D experience in games. From the very beginning of its existence, it was a highly specialized device designed just for transforming and rendering the given data, and there was an only one-way flow of data: from CPU to GPU.
However, since the arrival of Nvidia CUDA (Compute Unified Device Architecture) in 2007 and OpenCL (Open Computing Language) in 2009, the graphics processing units became accessible for general-purpose, bidirectional computations (called General-Purpose GPU Programming or simply GPGPU).
From my perspective as a .NET developer, it would be a great opportunity to have access to a huge computational power of hundreds GPU cores, so I tried to figure out what is the current state of the art in my domain.
First of all, what CUDA and OpenCL are and what are the differences between them?

Image 1. CUDA vs OpenCL
In general, they are APIs that allow a programmer to perform a specific set of computations on GPU (or even exotic devices like FPGA). It means that instead of rendering the result on display, the GPU will somehow return it to the API caller.
There are considerable differences between the two technologies.
Firstly, CUDA is a proprietary framework developed and supported only by Nvidia, while OpenCL is an open standard rather than a complete solution or concrete implementation. Therefore, CUDA is available only on Nvidia devices, while any manufacturer may support OpenCL (by the way, Nvidia chips support it as well).
Secondly, CUDA is a GPU-specific technology (at least now), while OpenCL interface may be implemented by various devices (CPU, GPU, FPGA, ALU, etc.).
These differences have obvious consequences:
- CUDA is a little bit more performant than OpenCL on Nvidia chips;
- You certainly can rely on consistency between CUDA documentation and implementation having a single manufacturer (Nvidia), which is not the case with OpenCL;
- OpenCL is the only way to go if you have to support hardware other than Nvidia chips.
How it works
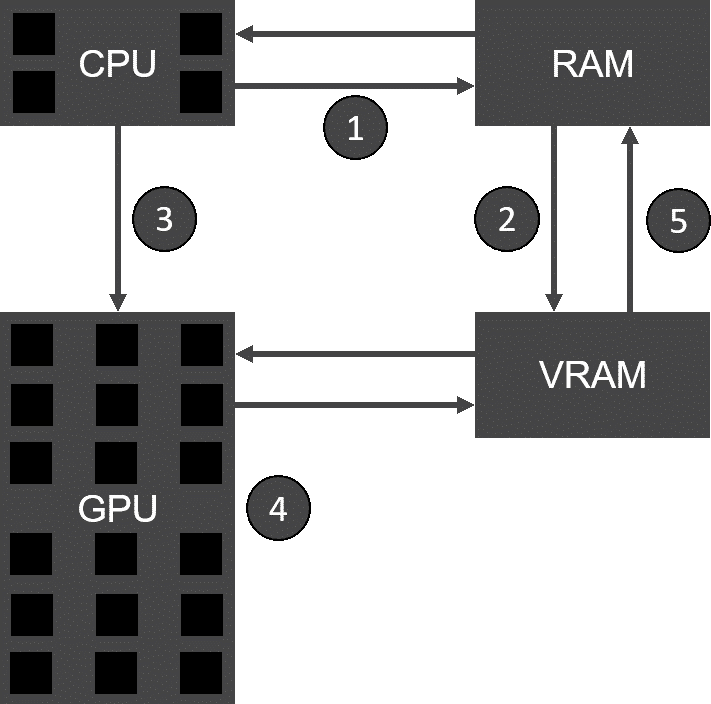
Image 2. CUDA processing flow
Let us describe how GPGPU works with the scheme represented in Image 2:
- Form the data to be processed in RAM
- Copy processing data into video RAM
- Instruct GPU to process the data
- Execute in parallel on each core
- Copy the result back to RAM
It should be noted that this kind of general-purpose GPU computations is reasonably restricted:
- they cannot perform any IO;
- they cannot directly reference data in computer memory.
Even though it seems simple on the general scheme, the computation model and API are not that intuitive, especially considering the fact that the native API itself is available only in C and C++.
Methinks it is the main reason why the GPGPU programming is not really widespread yet.
GPGPU on the .NET platform
There is no native support of GPU programming on .NET platform yet, so we will have to rely on third-party solutions. Moreover, there are not that many options to choose from, so let us briefly review available alternatives among actively developing projects. Interestingly, most of them focus on Nvidia CUDA rather than OpenCL.
Alea GPU by QuantAlea
Alea GPU is a proprietary CUDA-based library featuring free and commercial editions. Having even a free community edition allows you to produce commercial GPU-ready software for the consumer-level graphics cards (which are Nvidia GeForce series).
The documentation is really nice, with the samples provided both in C# and F#, and it also features really nice supplemental images. I would say that Alea GPU is the most mature, well-documented and easy-to-use solution at the moment.
Also, it is cross-platform and compatible with .Net Framework and Mono.
Hybridizer by Atimesh
Hybridizer is another commercial CUDA-based library, but I would not say it is comparable with Alea GPU in the sense of usability. Firstly, it is free for educational purposes only (but requires having a license anyway). Secondly, the configuration of the application is really awkward, since it requires to have an additional C++ project containing the generated code, which can be compiled only by Visual Studio 2015.
ILGPU by Marcel Köster
ILGPU is an open-source CUDA-based library featuring nice documentation and samples. It is not as abstract and easy-to-use as Alea GPU, but anyway it is an impressive and solid product even being developed by a single person.
Compatible with both .Net Framework and .Net Core.
Campy by Ken Domino
Campy is another example of an interesting open-source library being developed by a single programmer. It is still in early beta, but promises to have a really high-level API. It is built upon .NET Core.
I tried to use each of the mentioned solutions, but Hybridizer appeared too awkward to configure, while Campy simply did not work on my hardware. Therefore, we will proceed with our evaluation with Alea GPU and ILGPU libraries.
Evaluation
To have a taste of GPGPU programming on .NET, we will implement a simple app that will transform a set of images applying a simple filter to them.
There are going to be three implementations for comparison:
- Using standard Task Parallel Library of .NET Framework;
- Using Alea GPU;
- Using ILGPU.
Since both libraries use CUDA, we will have to have an Nvidia device. Fortunately, I’ve got one.
In general, my workstation is a mid-range PC with the following specs:
- CPU: Intel Core i5-4460 (4 cores no Hyper-Threading, 3.20 GHz base clock speed);
- GPU: Nvidia Geforce GTX 1050 Ti (768 CUDA Cores, 4 GB GDDR5 VRAM, 1290 MHz Clock base clock speed);
- RAM: 32 GB DDR3;
- Storage: Samsung SSD 850 EVO 250 GB (which is not really necessary);
- OS: Windows 10 Pro;
Before we proceed, we will have to install the CUDA Toolkit (required by ILGPU, not AleaGPU) from the official web site: https://developer.nvidia.com/cuda-downloads
Both libraries are cross-platform, but since Alea GPU is not yet adapted for .NET Core, we will create a Windows-based console app using the last .Net Framework installed on my workstation (which is 4.7.1).
I will use the following Nuget packages:
- Install-Package Alea – Version 3.0.4
- Install-Package FSharp.Core – Version 4.5.0
- Install-Package ILGPU – Version 0.3.0
- Install-Package SixLabors.ImageSharp – Version 1.0.0-beta0004
FSharp.Core is required by Alea GPU, because it is built upon it.
ImageSharp is a nice cross-platform image processing library, which will simplify the process of reading and saving the image data for us.
General program flow
Our program is going to be quite straightforward consisting of the following steps:
- Load image using ImageSharp Image class;
- Get an array of pixels (represented by Rgba32 structure);
- Transform the array of pixels (inverse the colors);
- Reload them into Image object;
- Save result into output directory.
Image<Rgba32> image = Image.Load(imagePath);
Rgba32[] pixelArray = new Rgba32[image.Height * image.Width];
image.SavePixelData(pixelArray);
string imageTitle = Path.GetFileName(imagePath);
Rgba32[] transformedPixels = transform(pixelArray);
Image<Rgba32> res = Image.LoadPixelData(
config: Configuration.Default,
data: transformedPixels,
width: image.Width,
height: image.Height);
res.Save(Path.Combine(outDir, $"{imageTitle}.{tech}.bmp"));transform is the function of the following signature: Func<Rgba32[ ], Rgba32[ ]>
We are going to have a distinct implementation of this function for each chosen technology.
TPL IMPLEMENTATION
The Task Parallel Library is a standard and friendly way of handling parallelism and concurrency in .NET framework. The code below, implementing out simple image filter, hardly requires any comments. I should only note that I do mutate the pixel array passed to the Apply method to gain better performance, even though I discourage such functions.
public static class TplImageFilter
{
public static Rgba32[] Apply(Rgba32[] pixelArray, Func<Rgba32, Rgba32> filter)
{
Parallel.For(0, pixelArray.Length, i => pixelArray[i] = filter(pixelArray[i]));
return pixelArray;
}
public static Rgba32 Invert(Rgba32 color)
{
return new Rgba32(
r: (byte)~color.R,
g: (byte)~color.G,
b: (byte)~color.B,
a: (byte)~color.A);
}
}ALEA GPU IMPLEMENTATION
Considering the below filter implementation in Alea GPU, we should admit that there is no real difference with the previous TPL example. The only noticeable change is the Invert method, where we had to use the parameterless constructor for Rgba32 structure, this is the current limitation of the code run by Alea GPU.
public class AleaGpuImageFilter
{
public static Rgba32[] Apply(Rgba32[] pixelArray, Func<Rgba32, Rgba32> filter)
{
Gpu gpu = Gpu.Default;
gpu.For(0, pixelArray.Length, i => pixelArray[i] = filter(pixelArray[i]));
return pixelArray;
}
public static Rgba32 Invert(Rgba32 from)
{
/* Noticeable that Alea GPU only support parameterless constructors */
var to = new Rgba32
{
A = (byte)~from.A,
R = (byte)~from.R,
G = (byte)~from.G,
B = (byte)~from.B
};
return to;
}
}ILGPU IMPLEMENTATION
ILGPU API is much less abstract compared to the previous ones. First of all, we have to explicitly select a processing accelerator. Secondly, we need to explicitly load a kernel, which is a static function that is going to be run by GPU cores in order to transform our data. The kernel function is very restricted: it cannot operate reference types and surely cannot perform IO. Thirdly, we need to allocate memory in GPU RAM and load our data into it before starting the transformation process.
public class IlGpuFilter : IDisposable
{
private readonly Accelerator gpu;
private readonly Action<Index, ArrayView<Rgba32>> kernel;
public IlGpuFilter()
{
this.gpu = Accelerator.Create(
new Context(),
Accelerator.Accelerators.First(a => a.AcceleratorType == AcceleratorType.Cuda));
this.kernel =
this.gpu.LoadAutoGroupedStreamKernel<Index, ArrayView<Rgba32>>(ApplyKernel);
}
private static void ApplyKernel(
Index index, /* The global thread index (1D in this case) */
ArrayView<Rgba32> pixelArray /* A view to a chunk of memory (1D in this case)*/)
{
pixelArray[index] = Invert(pixelArray[index]);
}
public Rgba32[] Apply(Rgba32[] pixelArray, Func<Rgba32, Rgba32> filter)
{
using (MemoryBuffer<Rgba32> buffer = this.gpu.Allocate<Rgba32>(pixelArray.Length))
{
buffer.CopyFrom(pixelArray, 0, Index.Zero, pixelArray.Length);
this.kernel(buffer.Length, buffer.View);
// Wait for the kernel to finish...
this.gpu.Synchronize();
return buffer.GetAsArray();
}
}
public static Rgba32 Invert(Rgba32 color)
{
return new Rgba32(
r: (byte)~color.R,
g: (byte)~color.G,
b: (byte)~color.B,
a: (byte)~color.A);
}
public void Dispose()
{
this.gpu?.Dispose();
}
}SIMPLE PERFORMANCE TEST
Finally, we need to measure the speed of image transformations. In order to do that I will use a standard Stopwatch class:
var stopwatch = new Stopwatch();
foreach (string imagePath in imagePaths)
{
/* Some Code */
stopwatch.Start( );
Rgba32[ ] transformedPixels = transform(pixelArray);
stopwatch.Stop( );
/* Some Code */
}
Console.WriteLine($"{tech}:\t\t{stopwatch.Elapsed}");Note that to have a clean test, I only measured the time of transformation itself, not taking into account IO operations.
For the test data I used several high-resolution photos made by Hubble telescope.
![]()
Running the program on my particular workstation, I’ve got the following average results:
- TPL: 0.737472333 seconds
- Alea GPU: 0.4567708 seconds
- ILGPU: 0.410849867 seconds
So, in this particular case the least abstract approach provided by ILGP appeared to be the fastest one offering almost 80% win in performance.
So, what does it mean and is it even worth it?
On the one hand it isn’t that great win, although I am pretty sure, that my way of using the available API wasn’t optimal.
On the other hand, it is already great, considering that we did transform the images noticeably faster and our CPU remained free and available for another kind of work!
CONCLUSION
General-purpose GPU programming on a high-level language like C# is real fun and I would highly suggest you play around with the libraries like Alea GPU or ILGPU. I do believe that tomorrow many of us will program in heterogeneous computation environments consisting of different kind processing units, and we should learn how to utilize their powers.
I hope to have native support of GPU programming in .NET somewhere in the future. It would be great if Microsoft makes TPL compatible with OpenCL standard. Another amazing option would be if Microsoft acquires Alea GPU as it did with Xamarin. Considering Nvidia Tesla GPUs in Azure it sounds reasonable.
All the source code is available at my GitHub: https://github.com/NicklausBrain/GpGpuViaCs-2018
Your comments and critics are welcome. Perhaps you can point at my misuse of the API, so that I can further improve the performance.


