




















Data Warehouse, Data Lake, and Data Lakehouse are the most popular types of data storage architectures that may serve as a benefit to any business looking to develop their analytics capabilities. Each of them has a set of advantages and best-fit use cases. The most important thing is to choose the data storage approach that suits your business needs in the best way. In this blog post, we'll describe the workings of each solution to help you make a more informed decision.
Data storage architecture is a hot topic in today’s business world as the demand for big data analytics is growing. Businesses generate massive amounts of data and require a robust solution to collect, store, and analyze it effectively. Data storage is the foundation of big data architecture and its components. It provides an environment for storing and serving data and has a direct influence on important KPIs, such as:
- Time-to-insight & Query Response Time
Efficient storage solutions can dramatically reduce query processing and retrieval time. Thus, businesses get information faster, can timely spot inefficiencies or opportunities, and react to them more effectively. - Data Availability
Easy access to data means it’s available at the right time, allowing businesses to use it at the exact point they need insights. This, in turn, contributes to higher operational efficiency and better quality decision-making. - Cost
Optimized data storage solutions help companies reduce hardware, cloud infrastructure, and/or software license costs. Also, businesses can scale their systems up and down depending on their needs with a reasonable budget and effort.
Therefore, it’s important to choose the right data storage type and optimize it for your current and future needs to ensure optimal performance over time.
Historically, the two most popular approaches to storing and managing data are Data Warehouse and Data Lake. The choice between them usually depends on business objectives and needs. While Data Lakes are ideal for preserving large volumes of diverse data, warehouses are more favorable for business intelligence and reporting. Sometimes, organizations try to have the best of both worlds and mix Data Lake & Data Warehouse architectures together. This, however, can be a time and cost-consuming process.
Against this backdrop, a new hybrid approach – Data Lakehouse has emerged. It combines features of both Data Lake and Data Warehouse, allowing companies to store and analyze data in the same repository and eliminating the Data Warehouse vs. Data Lake dilemma. Data Lakehouse mixes the scalability and flexibility of a Data Lake with the ability to extract insights from data easily. Ever so compelling, this approach still has certain limitations and should not be treated as a “one-size-fits-all” solution.
What Is a Data Warehouse?
Data Warehouse is a centralized repository for the storage of structured data. The data flows into the storage from various sources and undergoes a processing stage before hitting the Warehouse repository. Data Warehouse storage is designed as a well-organized library of data that can be easily retrieved and analyzed. Hence, organizations get insights faster, which improves their operations and decision-making. Also, with its organized data, Data Warehouse serves as a basis for conducting effective BI analysis.
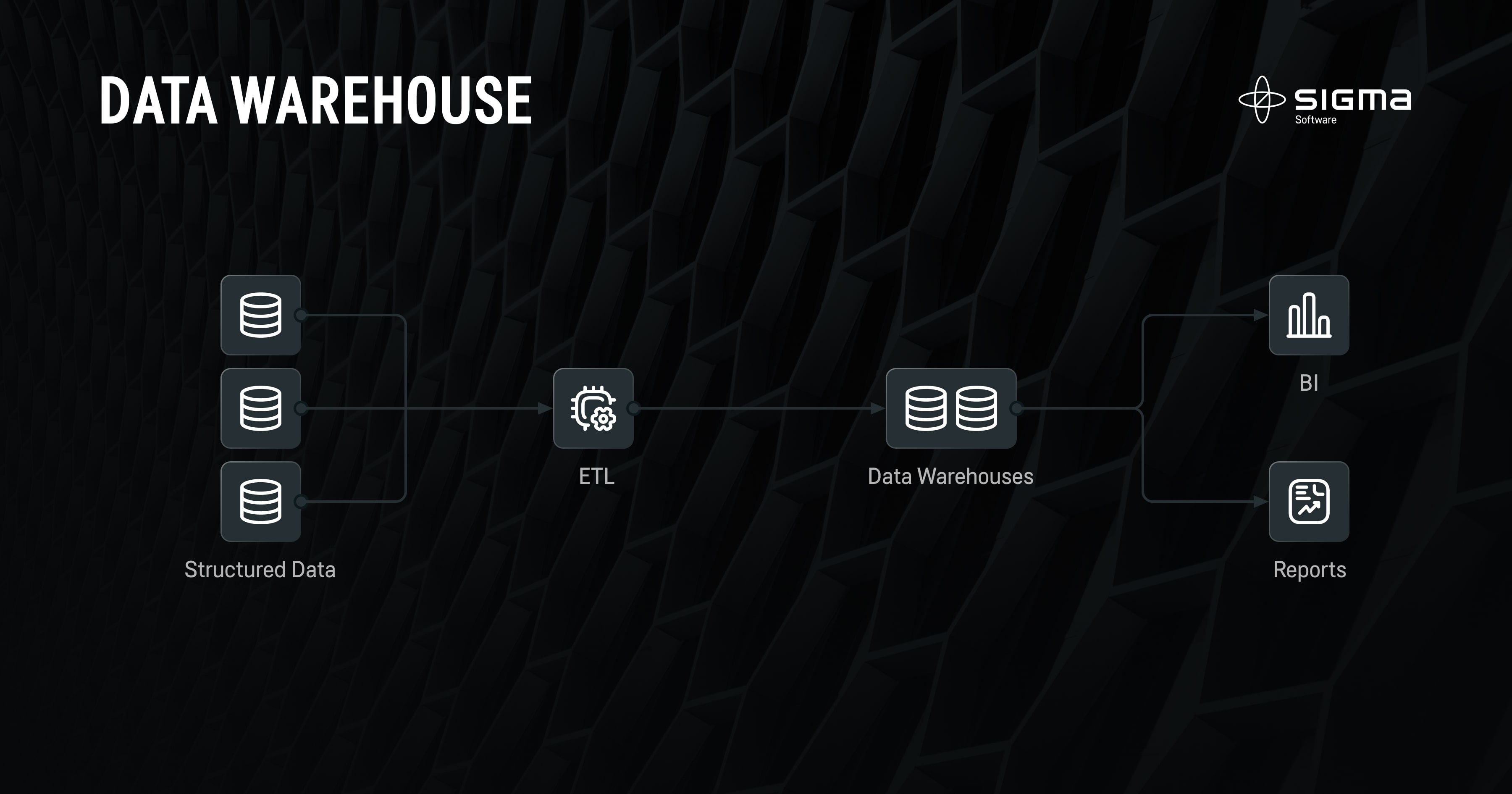
Pros of a Data Warehouse
The Data Warehouse is a powerful solution for organizations that want to structure large volumes of data and improve analytics. Businesses can take advantage of its well-organized storage and out-of-the-box features that empower organizations to gain insights quickly and easily:
Enhanced ETL performance
ETL (Extract, Transform, Load) is a data integration process that helps organizations prepare their data for advanced analytics. Data Warehouse storage is the right choice for maximizing the efficiency of the ETL due to its structured organization and fast query processing capabilities. This, coupled with data transparency, speeds up the ETL pipeline development, making the overall process faster and more efficient compared to other storage options like Data Lake. The efficient ETL process, in turn helps organizations streamline their data integration efforts and ensure data consistency across multiple sources.
Higher security
A structured data organization provides more granular data protection. Modern Data Warehousing systems typically offer advanced security features off-the-shelf, including column-level and row-level security. Modern Data Warehouse solutions also have built-in encryption and access control mechanisms that fully comply with GDPR requirements. This increases data protection from unauthorized access and potential breaches.
Fast query processing
The query processing in Data Warehouses is usually faster than in any other type of data storage. Data Warehouses are originally optimized to process large and complex datasets. They safeguard fast querying through well-structured data organization, data storage in a columnar format, and extensive dataset partitioning. Thus, businesses get the necessary information swiftly and can react to uncovered inefficiencies or opportunities faster than competitors.
Cons of a Data Warehouse
Data Warehouses produce significant benefits for organizations that need to store, organize, and analyze large data volumes. Yet, they also have some drawbacks that businesses should consider before implementing a Data Warehouse solution.
Complex data design
The process of creating a well-structured data repository requires experience and knowledge in data engineering. So, setting up efficient tables and data relationship design in a Data Warehouse is a complex and challenging task for organizations lacking relevant technical expertise.
Limited agility
Data Warehouse only stores certain data that is transformed and structured for particular use cases. Hence, if a business happens to change or expand its analytics objectives at some point in the future, the stored data may not be enough to fully meet those needs. So, when an organization wants to analyze all their incoming data, both structured and unstructured, they need extra tools and solutions to make this possible. This also includes additional time, effort, and costs to modify existing ETL processes, adding new data sources, or setting up integration with external tools and platforms.
High costs
Data warehousing costs are typically higher than other data storage solutions due to the comprehensive analytical capabilities it provides. The price varies depending on the storage size, data complexity, processing tools, deployment model (cloud, on-premises), and the chosen platform. It is also necessary to consider the costs of ongoing support and maintenance of your Data Warehouse. These tend to grow over time, as the more data you store, the more you can expect to pay.
Best-fit use cases for a Data Warehouse
Each organization has unique data management needs based on the industry, amount of data stored, business objectives, and goals. Data Warehouse offers powerful tools but is still not a one-size-fits-all solution. However, there are many business scenarios where a data warehousing strategy works best.
Business Intelligence analytics
BI analysis requires accurate, consistent, and well-structured data to perform complex research and generate insights for businesses. Data Warehouses are the ideal solution for this since they offer both a repository for structured data and built-in analytical tools. As a result, BI experts can efficiently analyze data to identify trends/patterns and perform predictive analytics.
Supply chain operations improvement
Supply chain organizations operate large data volumes daily and need data to be processed swiftly with response time being minimized. Data Warehouse stores the data in an organized tabular format right away for easy navigation and incorporates multiple ready-to-use query tools for prompt data collection and retrieval. This makes sure that all the supply chain-related processes receive necessary insights quickly and always on time.
Evolution of Marketing & sales campaigns
Most Data Warehouses involve OLAP (online analytical processing) functionality. This allows users to run flexible analysis of data from different perspectives like time, geography, product, etc. Hence, organizations may segment their audience and create targeted marketing campaigns that resonate with specific customer groups. Additionally, a large amount of historical data helps businesses track the effectiveness of marketing and sales activities. For example, Walmart uses a Data Warehouse to analyze customers’ previous shopping experiences and track customer behavior to reveal areas for service improvement.
Financial data & trend insights
Financial data is often complex and comes from multiple sources. Data warehousing enables businesses to preserve a large volume of structured historical data in centralized storage, providing a broad overview of all financial flows. This in turn simplifies pattern identification and analysis for experts. As an example, Starbucks processes 90 million transactions per week and stores transaction data in a Data Warehouse to further analyze and identify tendencies, optimize sales, and make accurate predictions on future performance.
What Is a Data Lake?
Unlike Data Warehouse, Data Lake allows businesses to store and process data in various formats (structured, unstructured, and semi-structured) and types (audio, video, and text) in one centralized repository.
According to the 451 Research’s report, Data Lake is a popular solution for businesses of all sizes, as (71%) of enterprises are currently using or piloting a Data Lake environment or plan to do so within the next 12 months.
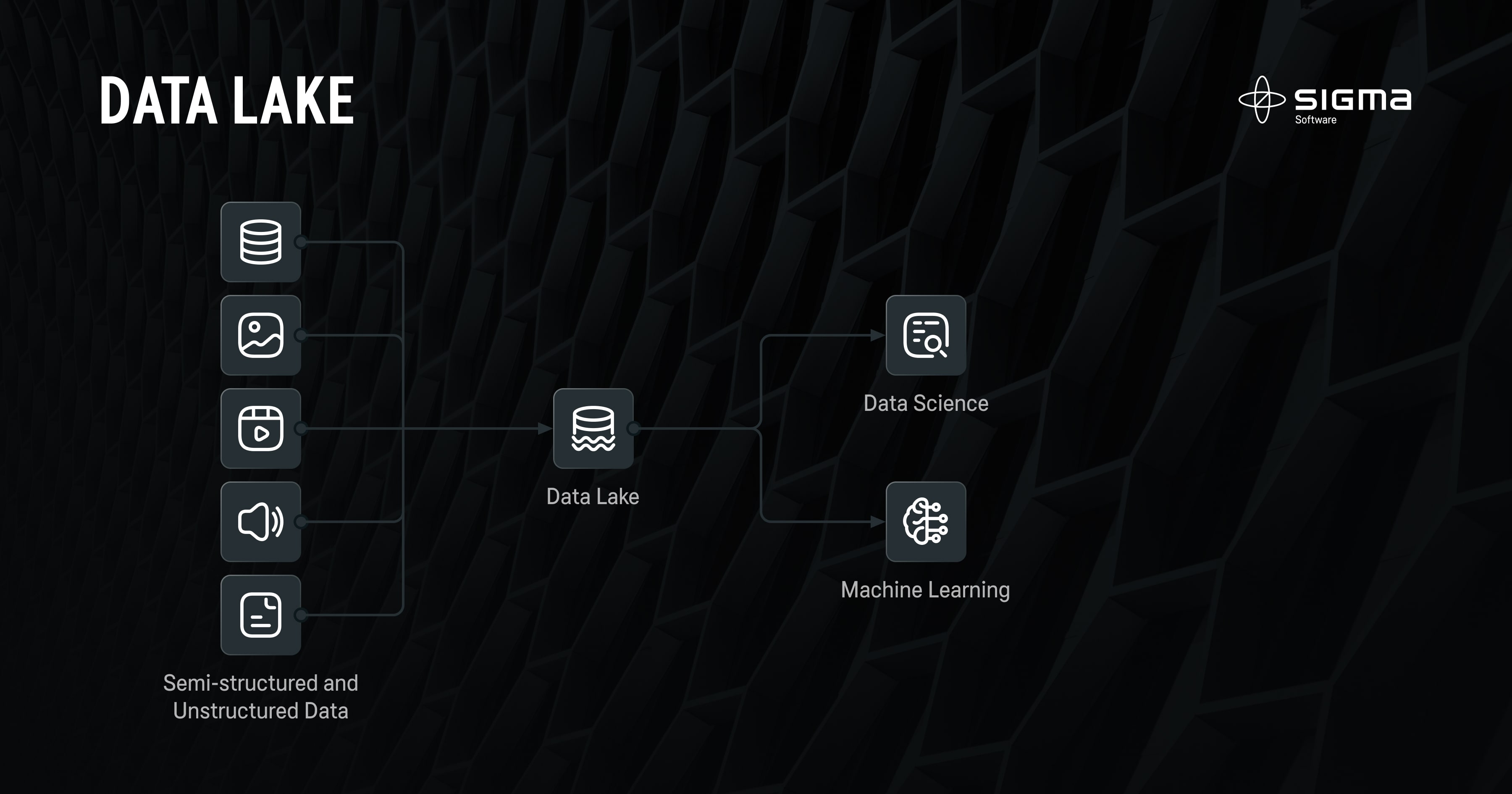
Pros of a Data Lake
One distinct feature of Data Lake is that it provides no limits as to data format structure, type, or amount and guarantees that businesses can extract insights from any section of their data at any time. Other advantages of Data Lake include:
High agility
Since Data Lake has no strict requirements for receiving only structured data, it gives organizations more space for maneuvers with analytics. Moreover, businesses may benefit from the ability of Data Lake to accommodate growing data volumes easily. It is often built on distributed storage systems such as Hadoop Distributed File System (HDFS) or Amazon S3, which is able to be scaled up and down when needed. As a result, organizations can extend their storage with new data sets, types, and sources without significant changes to its architecture.
Lower costs
Data lakes are less expensive than Data Warehouses as they don’t require any transformations or pre-processing of data before storage. When talking about Cloud Data Lakes, the storage is generally very affordable, for example:
| Cloud provider | Pricing |
| Amazon Web Service S3 storage | Start at $0.023 per GB per month |
| Azure Data Lake Storage Gen2 | Starts at $0.015 per GB per month |
| Google Cloud Storage | Starts at $0.020 per GB per month |
However, the overall TCO (Total Cost of Ownership) of analytics depends not only on the storage pricing but also on the data processing cost. While Data Lake has lower rates for data storage, the pricing for processing is usually higher than in a Data Warehouse. The complex querying in an unstructured Data Lake repository requires additional effort and more processing power to get the relevant information, which results in higher costs. So, it’s essential to shape your current and future needs beforehand to make sure you won’t incur unnecessary expenses over time.
Cons of a Data Lake
Data Lake can be a powerful tool for managing large and diverse data sets, but it also has drawbacks and limitations. Thus, businesses should weigh the potential challenges that come with utilizing this type of data storage:
Lack of structure
Extraction of specific data from the Lake can be challenging as unstructured data requires more time for queries and management. The Lack of structure also affects data transparency, as it is harder to ensure data is stored accurately and consistently. Moreover, without appropriate data governance, a Data Lake risks becoming a data swamp – storage containing chaotic data that has poor value for a business. This can be treated by setting up a proper governance strategy to ensure Data Lake is a valuable asset. However, it usually takes additional time and effort for implementation.
Security challenges
Data Lakes contain vast amounts of data in various formats that come from different sources. So, it may be challenging to identify security threats or vulnerabilities going through a large unorganized Data Lake storage.
Query execution
By default, Data Lakes have no query processing capabilities and need additional big data tools and technologies such as Apache Spark and SQL query engines to run analytics on them. Hence, query processing requires more time, effort, and expertise.
Best-fit use cases for a Data Lake
The most common use cases for Data Lake involve storing and processing massive volumes of diverse data sets in their raw format. Therefore, this approach can cover any business need that corresponds to these two sets of criteria:
Data Science
Data scientists need to easily access diverse data sets from multiple sources to build their models. Data Lake is a centralized repository of versatile data by design. It provides data scientists with the perfect environment to experiment with different data sets, test hypotheses, and refine their models.
Machine Learning projects
ML domain is highly dependent on big volumes of diverse unformatted data to train algorithms and models. Data Lake is all about storing massive amounts of data from multiple sources, including data generated by IoT devices, social media, etc.
Gathering Marketing Insights
Marketers are always looking for ways to gain a deeper understanding of their audience and the latest tendencies to create personalized campaigns and improve customer satisfaction. Data Lake allows users to run analytics and investigations from numerous perspectives. Thus, experts may derive unique insights into customer behavior, trends, and even correlations between data they don’t usually track. This uncovered information can reveal more opportunities for a business, helping marketers create effective strategies, increase customer loyalty, and gain a competitive edge.
What Is a Data Lakehouse?
Businesses rarely use Data Lake in its pure format. In most cases, they not only need to store data but also effectively process the data. Thus, most companies chose to go with a hybrid approach where Data Lake is appended by a Data Warehouse. The latter acts as a layer on top of the Data Lake and provides a structured and optimized environment for analytics, reporting, and BI. This approach allows users to combine the capabilities of a Data Lake and Data Warehouse and analyze massive amounts of diverse data effectively.
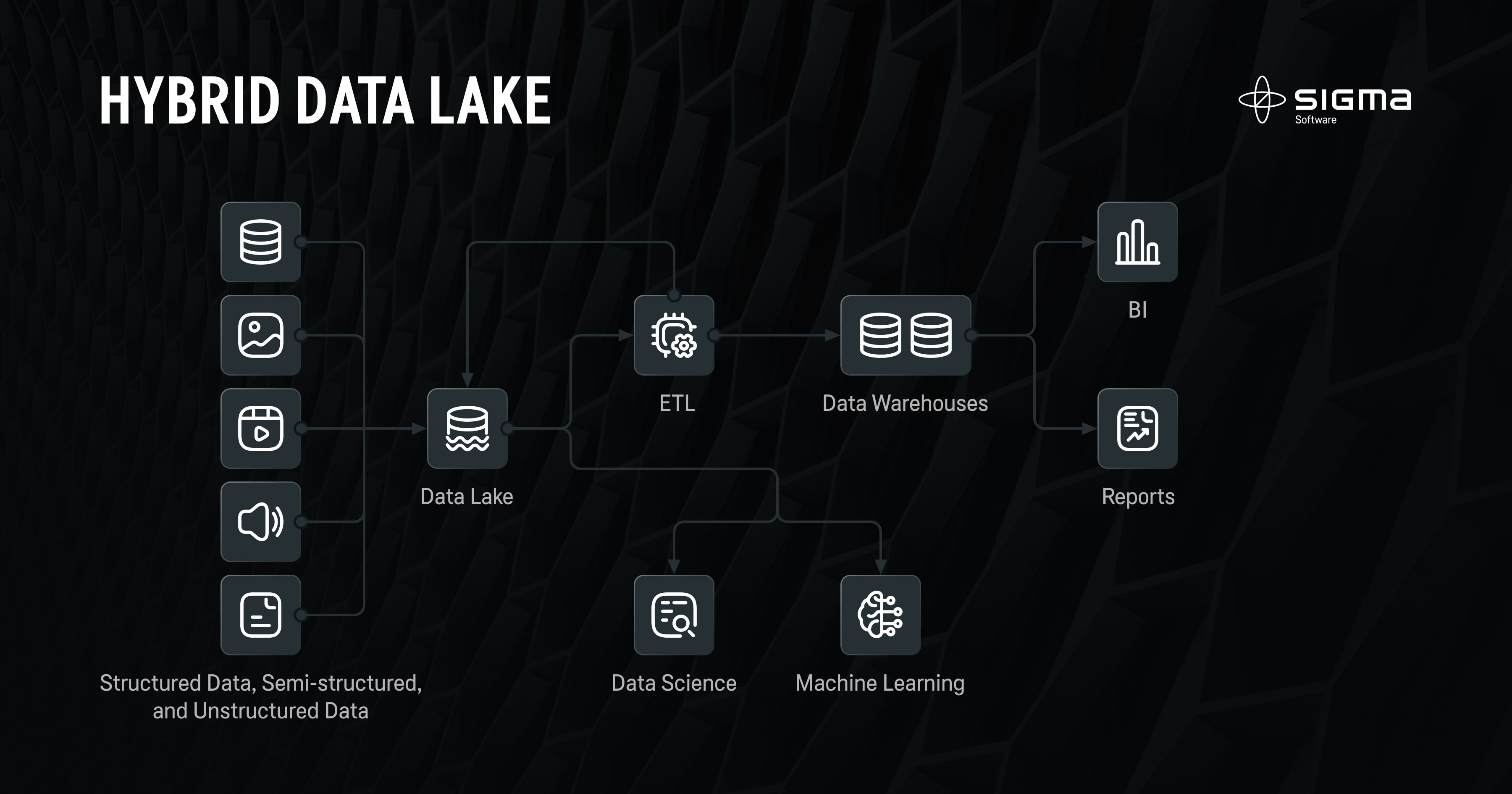
However, this approach has a significant drawback – an expensive and complex setup. Unlike Data Warehouse and Data Lake, it not only requires expertise, but time, costs, and extra effort to integrate with other services and platforms. This Hybrid approach has served as a foundation for a new type of data storage known as Data Lakehouse.
The newest approach combines the benefits of both a Data Lake and a Data Warehouse out-of-the-box and has a fast and easy setup process. Data Lakehouse enables businesses to store data in raw formats and also provides a pre-defined structure for data analytics. This is possible due to the layered Data Lakehouse architecture that combines structured and unstructured data within one repository. Thus, Data Lakehouse supports BI, ML, and data science in one platform.
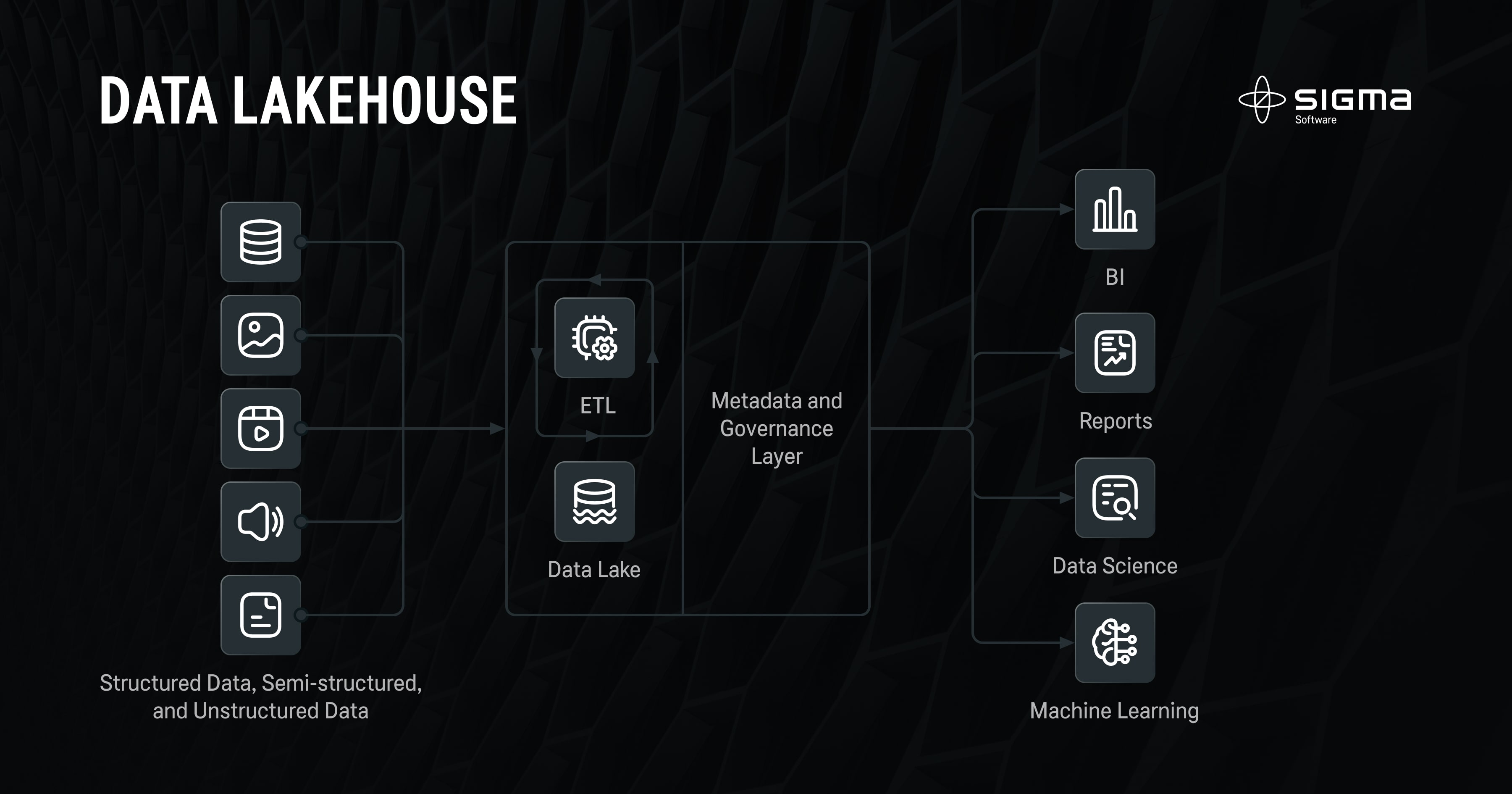
Pros of a Data Lakehouse
Data Lakehouse combines the best features of both Data Warehouse and Data Lake. It may provide organizations with a solution to the Data Lake vs. Data Warehouse dilemma and offers advantages, including:
Scalable repository
Data Lakehouse can preserve large volumes of data and be easily scaled by adding more servers or nodes to the system. Hence, if the volume of stored data drastically increases, it has little effect on performance.
Reasonable costs
Data Lakehouse allows businesses to get the features and benefits of Data Lake and Data Warehouse in one place. This significantly cuts costs, as businesses do not have to pay for two sets of storage. Moreover, Data Lakehouse architecture does not require upfront data modeling in the same way as Data Warehouse. Instead, it leverages open-source technologies such as Delta Lake to bring reliability to unstructured data at a lower cost.
Improved data governance
The built-in features of Data Lakehouse provide advanced data governance capabilities for managing data quality, security, and privacy in a centralized manner. Moreover, most providers of Data Lakehouse offer ACID compliance by default. Thus, they ensure accurate, reliable data transactions and safeguard compliance with regulations such as GDPR.
Fast set up
Data Lakehouse offers ready-made functionality for data processing. Therefore, organizations can easily start running their analytics without setting up and integrating additional tools, as in Data Lake. As a result, the analysis of massive data amounts becomes faster and more effective.
Cons of a Data Lakehouse
Appealing as it may be, Lakehouse still has a number of drawbacks, including:
Vendor lock
There are only a few providers of Data Lakehouse (Databriсks, Dremio), so the choice of platforms for its implementation is limited compared to the other storages. The lack of alternatives creates challenges for businesses as there are not many options to choose from. Moreover, this also brings additional challenges if organizations need to switch or expand to another platform.
It is also possible for businesses to build their own open-sourced Data Lakehouse, but it would not be as feature-rich as the ones provided by vendors. Therefore, organizations should carefully consider the long-term scalability and flexibility of the chosen Data Lakehouse solution to mitigate any potential risks if they do so.
Flexibility constraints
The built-in feature set of Data Lakehouse has some limitations in terms of customization capabilities. So, if an organization needs to modify the Lakehouse architecture at a certain point in time, this may unveil diverse hidden complexities and may require substantial investment.
Best-fit use cases for a Data Lakehouse
Data Lakehouse is a go-to solution for organizations seeking to run both Data Warehouse- and Data Lake-like operations on the same data within a single platform. Moreover, this approach is an ideal option for those looking for a fast launch, as Data Lakehouse provides robust functionality by design.
Nevertheless, you should carefully approach the off-the-shelf options and make sure that those address your needs in full. Otherwise, going beyond the default functionality can take tangible effort and investment.
Data Lakehouse, Data Warehouse, or Data Lake: Which is better to use?
The Data Lakehouse vs. Data Warehouse vs. Data Lake debate is ongoing. The choice of a suitable data storage architecture depends on several factors and can become a challenge for businesses. In a nutshell, the major differences between all three approaches are as follows:
| Criteria | Data Lakehouse | Data Warehouse | Data Lake |
| Data organization | Structured, semi-structured, and unstructured data | Structured data | Semi-structured, unstructured data |
| Query response speed | Moderate query performance | Fast query performance | Slow query performance |
| Scalability | Easy to scale, moderate cost for scaling | Hard to scale, requires extra costs & efforts | Easy to scale, low cost for scaling |
| Agility | High agility | Limited agility | High agility |
| Security | User-based access policies Row-level security Column-level security | User-based access policies Row-level security Column level security Dynamic Data Masking SSL connectivity | User-based access policies |
| Use cases | Combination of AI, ML & Data Science activities Fast and easy start | BI activities Real-time analytics | ML and Data Science activities Historical data preservation |
| Cost of storage | Low | High | Low |
| Cost of processing | Moderate | Low | High |
| Cost of setup | Moderate | High | Low |
The cost of change, if you’ve chosen the wrong data storage architecture type, is usually high. So, it is critical to opt for an approach that suits your business criteria best. This decision requires deep expertise and experience in working with different types of data storage. Hence involving an expert will help you make the right choice and make things much easier in the end.
For situations where you still doubt your use case and are not quite sure about future plans, you can take the safe route and opt for a Data Lakehouse approach. This can also be a good compromise when you lack relevant data modeling expertise in-house yet have some basic knowledge of analytics, know the type of data you operate, and where it will be stored. You’ll be able to configure and manage such storage yourself without spending money on additional expertise.
If you want a robust solution to perfectly cover your needs, you should carefully benchmark your use case against available storage alternatives on the market and make sure that the chosen solution is the right option for all your requirements.
Contact us if you are pondering which data storage solution to choose or need support configuring
one – our expert team will provide you with end-to-end assistance from best-fit data storage architecture selection to solution integration and ongoing support.


