
CONTENTS

USA
Thank you for reaching out to Sigma Software!
Please fill the form below. Our team will contact you shortly.
Sigma Software has offices in multiple locations in Europe, Northern America, Asia, and Latin America.
USA

Sweden

Germany

Canada

Israel

Singapore

UAE

Australia

Austria

Ukraine

Poland

Argentina

Brazil

Bulgaria

Colombia

Czech Republic

Hungary

Mexico

Portugal

Romania

Uzbekistan
13 min read
Until now, it was hard to call functional programming a mainstream practice. It still remains not well understood and is perceived as a topic rather obscure if not with the enigmatic halo and awe.
Even though respected gurus like Robert Martin, Rich Hickey, Mark Seeman, and others try to promote it, not so many developers practice it consciously. Nevertheless, the functional paradigm itself slowly but surely sneaks into our general-purpose languages and tools sometimes giving new names and applications to fairly old concepts. Just consider Reactive Extensions, React, Redux, LINQ, Java Streams, and C# 8 as a superficial example of this process. In this article, we will try to figure out what is the foundation of the functional paradigm. Why does it really matter? What features make it close to still dominant object-oriented programming?
When looking at the functional programming as a modern trend, it is interesting to note that this is in fact one of the oldest paradigms. It is even older then structural programming and the times when Go To statement became considered harmful! Here is a short list of programming paradigms with the respective time of their appearance:
So, the story begins back in 1958 with the creation of LISP, which was and remains an overwhelmingly powerful language, and you can learn more about it in our special article. LISP was created by John McCarthy who was a pioneer of Artificial Intelligence in the way that the term AI itself was coined by him. For the foundation of his new language, he took the concept of Lambda Calculus, a distinctive notation for function. That’s where the term “lambda” originally came from and then spread among various languages.
Lambda Calculus was developed in 30s by Alonzo Church and can be considered as an alternative to a Turing machine. In fact, both scientists were solving the same problem at the same time though they came up to it with different approaches. Turing machine is virtually a state machine, in other words it has a set of states and the rules of transition between them. Lambda calculus, on the other hand, does not operate the state at all, it is stateless. This difference in theoretical approaches led to fundamentally different designs of the future programming languages and was naturally reflected with the first two high-level languages: Fortran and LISP, respectively.
Programming in FORTRAN and its successors (including C, C++, Java) or any other imperative language is actually programming a state machine, while programming in LISP and functional languages looks like a composition of recursive functions.
This difference is so crucial that it actually affects the way of thinking.
At this point I should admit that, in reality, most of the functional languages allow a programmer to bring in some imperative code, though this is not “idiomatic” way and rarely justified.
Over time, there were many functional languages developed, let’s mention the most prominent ones:
There is a troubling question of why functional languages were almost completely whipped out of the industry and given up the market to imperative (procedural and later object-oriented) languages? Wasn’t that an evidence of their inferiority and if so, why are we experiencing the comeback of functional practices nowadays?
For that reason, we should point out that functional languages being declarative are indeed more abstract and expressive, but such qualities cannot be easily achieved without trade-offs in performance. Therefore, imperative languages appeared to be superior at the time when personal computers were rising, and every byte counted.
Nevertheless, functional languages did survive. Firstly, they were continuously evolving in the academic environment for an obvious reason of closeness to math together with the availability of powerful mainframes. Secondly, functional languages were constantly finding application in solving cutting-edge problems even by private companies. One of the prominent applicants was Xerox, which employed LISP in its pioneering workstations that featured one of the first graphical user interfaces. Another but truly remarkable was the experience of employing the Erlang system by Ericson in building distributed telecom systems. It appeared that building the same system in functional Erlang compared to C++ shortens the codebase three times, while almost doubling the performance!

This is an important point, because previously we admitted that declarative expressiveness indeed comes with a trade-off in performance, and this is still true, while another truth is that imperative approaches cease to work at some degree of system complexity. For simplicity it can be explained in two ways: either human intelligence fails to efficiently model a distributed system like a state machine or a state machine is an incorrect way to model such systems. Keeping that in mind, let’s take into account the radical change in the hardware we experienced during the last decade and a half (Images 1-3). We came from single-processor workstations to dozen-core smartphones, while the line between fast RAM and formerly slow persistent storage is blurring. Modern software should utilize these powers efficiently and reliably. While the imperative approach naturally fits programming a single calculator such as the Turing machine, it seems to be not suitable for handling parallel, distributed, heterogeneous computations.
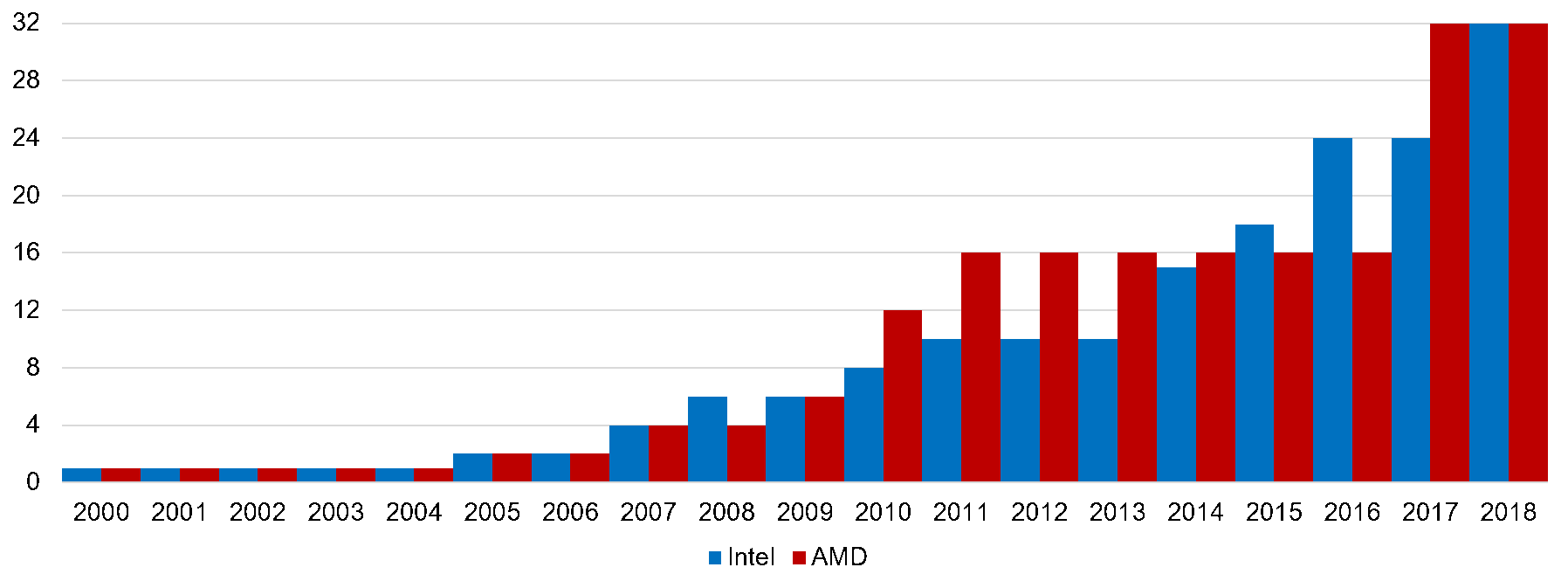
Image 1. CPU cores trend (cores/year)
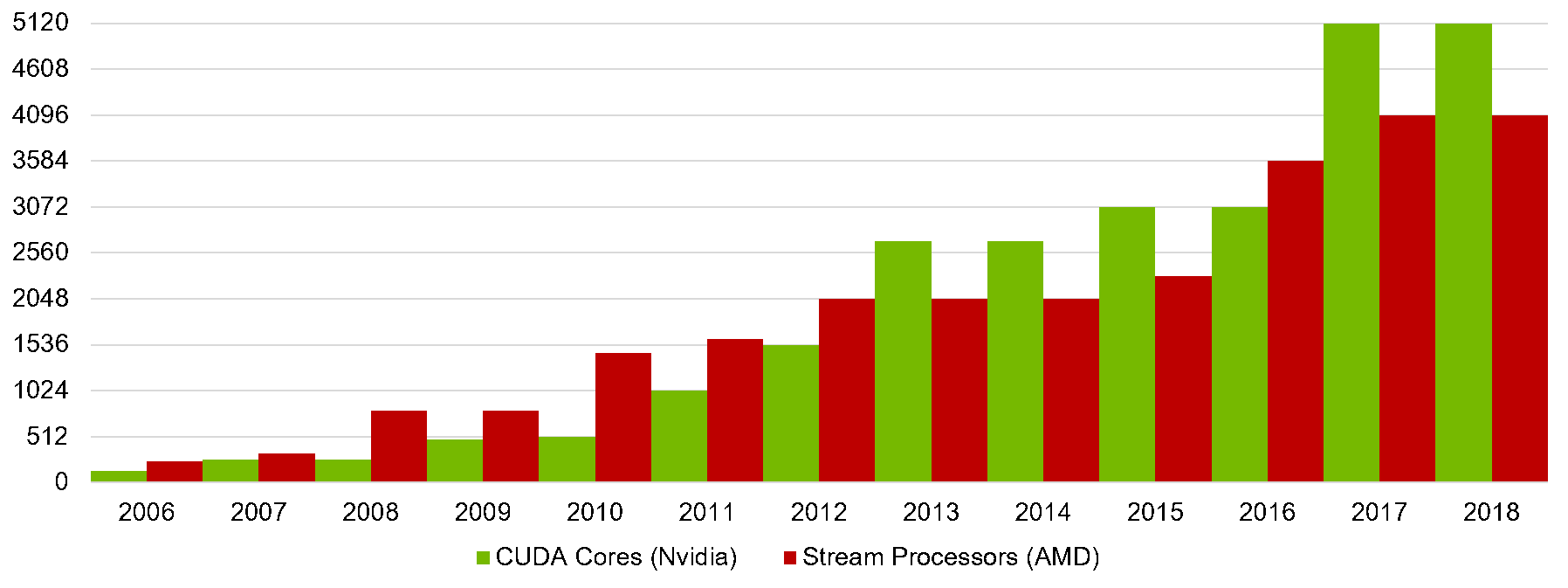
Image 2. GPU cores trend (cores/year)
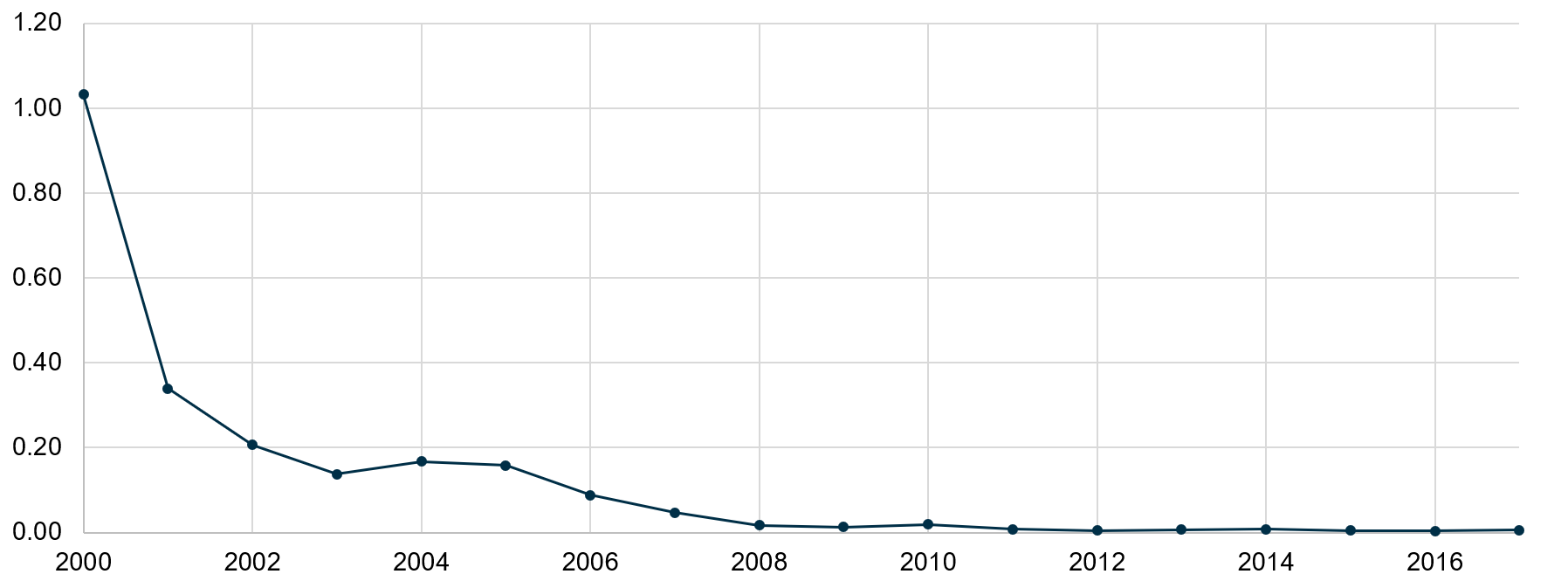
Image 3. RAM price trend ($ per Mbyte/year)
Every object-oriented developer should be well familiar with the so called Four Pillars OOP:
Since it is a familiar approach, it would be suitable to represent the key features of the functional paradigm in the same way.
So, the Four Pillars of the Functional Programming would be:
Herein below we will describe them precisely and see that in addition to them some OO features are not just achievable, but appear to be a natural part of functional languages as well.
Immutability is a default property of all functional data structures and variables, which means impossibility to change an object state once it was created.
Being a quite harsh and strange restriction at first glance, immutability appeared to be a really valuable property having the following benefits:
; Clojure (def animals (list "dog" "cat" "rat")) (cons "horse" animals) ; returns a new list of animals, not changing existing one
// F# let animals = ["dog";"cat";"rat"] let moreAnimals = List.append animals ["horse"] // returns a new list
// C#
var animals = new ReadOnlyCollection<string>(new [] { "dog", "cat", "rat" });
var moreAnimals = animals.Append("horse"); // returns a new EnumerableThere is still an important argument that arises against immutability, which claims on inefficeient memory consumtption caused by necessity to recreate an object each time we need to have it in a different state.
While being true, to some degree, that property of immutability has a relatively higher demand on memory, it isn’t that simple under the hood. In fact, functional languages heavily utilize the sharing of the data across created data structures, which is safe and intuitive optimization considering impossibility to change existing data.
Consider an example illustrated on Image 3: adding the “Rat” to the list of animals does not really recreate nor change existing list, this operation indeed creates a new list, but this new list consists of a new record plus reference to the existing list!
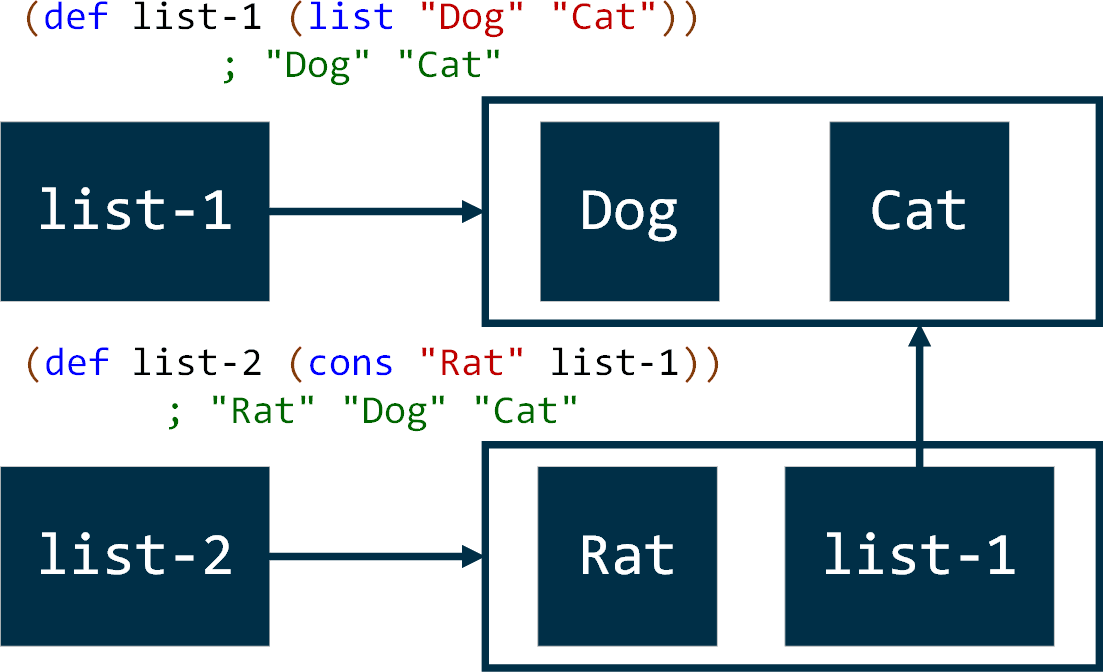
Image 4. Data sharing across immutable data structures
Now it is important to point out that demand of immutability should already be very close for developers familiar with the OO notion of encapsulation.
The notion of encapsulation is mainly risen as an attempt to make the flow of the program state more predictable, and the functional principle of immutability brings this quality to the extreme.
Another interesting quality of immutability is that you can consider it as a prototype pattern(link is external) built into language by default:
; Clojure
(defrecord color [R G B])
(def green ; create green color
(color. 0 255 0))
(def yellow ; create yellow from green
(update green
:R (fn [_] 255)))
(def red ; create red from yellow
(update yellow
:G (fn [_] 0)))
; no initial color changed its state:
; user=> green
; {:R 0, :G 255, :B 0}
; user=> yellow
; {:R 255, :G 255, :B 0}
; user=> red
; {:R 255, :G 0, :B 0}// F#
type Color = {
R: byte
G: byte
B: byte
}
// create green color
let green = { R = 0uy; G = 255uy; B = 0uy }
// create yellow from green
let yellow = { green with R = 255uy }
// create red from yellow
let red = { yellow with G = 0uy }
// no initial color changed its state:
// > green
// { R = 0uy; G = 255uy; B = 0uy }
// > yellow
// { R = 255uy; G = 255uy; B = 0uy }
// > red
// { R = 255uy; G = 0uy; B = 0uy }// C#
public class Color {
public Color(byte r, byte g, byte b) {
this.R = r;
this.G = g;
this.B = b;
}
public byte R { get; }
public byte G { get; }
public byte B { get; }
public Color WithRed(byte red) =>
new Color(red, this.G, this.B);
public Color WithGreen(byte green) =>
new Color(this.R, green, this.B);
public Color WithBlue(byte blue) =>
new Color(this.R, this.G, blue);
}
var green = new Color(0, 255, 0);
var yellow = green.WithRed(255);
var red = yellow.WithGreen(0);
/* Same behavior achieved in C# with significant extra code */
// > red
// { B=0, G=0, R=255 }
// > yellow
// { B=0, G=255, R=255 }
// green
// { B=0, G=255, R=0 }Purity is the property of functions not to have side-effects and any dependence on external state or time.
As we have already mentioned, Lambda calculus as the basis of functional programming, has nothing to do with the state or interaction with the real world, it’s just pure mathematical notation, therefore, such property is a default expectation from functional languages.
A function is considered pure when:
The property of purity has very similar benefits to the immutability:
We must confess that purity is not achieved that simple, since real software has to interact with the real world, and the real word has mutable states and changes over time. There are many approaches to that problem, it is not completely solved yet while the topic itself deserves an article of its own. Anyways, many functional languages allow having a mutable state as well as impure functions, although such possibility is intended to be used with caution and vigilance. Note how LISP and F# use a naming convention and special syntax to distinguish impure operations.
; in LISP (define (inc x) (+ x 1)) ; pure function (define i 1) (define (bad-inc!) (set! i (+ i 1))) ; impure function, changing global variable
// in F# let inc x = x + 1 // pure function // mutable variables in F# have to be declared explicitly let mutable i = 0 // impure function, changing global variable using special operator <- let badInc () = i <- i + 1
// in C# Math.Pow(2, 8); // pure function Path.GetTempFileName(); // impure function, returns randomized values DateTime.Now; // impure function, operates time
And again, the property of purity should be well familiar for OO developers who strive to cover their code with robust unit tests and isolate dependencies on file system, network, time, etc. In case of using functional languages, they enforce a developer to follow such discipline.
This feature is a really distinctive one and draws the line between languages that can be called functional and that can’t. If previous features (immutability and purity) indeed can be achieved by mere discipline, availability of first-class functions can be hardly determined by language. First-class functions is a feature of programming language to treat functions as a standard datatype, just like integers, characters, etc. In other words, it allows a programmer to create functions in runtime, pass them as function arguments, and return them from function calls.
Note that in this context you may often face another related term as “Higher-order functions.” To be precise, higher order functions is a limited feature compared to first-class functions, which allows a developer to pass functions as an argument or return as a result of function evaluation, but not necessarily creating them in runtime. In that way, a procedural language like C supports higher-order functions, but not first-class functions, therefore, cannot be called a functional language.
Treating functions as a separate datatype is a natural way to achieve polymorphism, in other words, ability of a single function (or algorithm) to process multiple datatypes. Therefore, all functional languages support polymorphism.
This can be easily understood from familiar object-oriented perspective when you consider a function signature as an interface, while every function with such signature is a respective implementation of such interface.
As an example of this quality, consider a sorting function, which is able to sort unlimited number of types by unlimited number of rules:
; Clojure (def numbers [7 4 1 2 3]) ; ascending is a first-class function, created at runtime (def ascending (fn [a b] (- a b))) ; sort is a higher-order function, taking comparison function as an argument (sort ascending numbers) ; (1 2 3 4 7) (sort (fn [a b] (- b a)) numbers) ; (7 4 3 2 1) ; Using data structures from previous example (def colors [green yellow red]) (defn luminance [color] (+ (* 0.2126 (:R color)) (* 0.7152 (:G color)) (* 0.0722 (:B color)))) ; Sort colors by luminance (sort (fn [c1 c2] (- (luminance c1) (luminance c2))) colors) ; red, green, yellow
// F#
let numbers = [7; 4; 1; 2; 3;]
// ascending is a first-class function, created at runtime
let ascending = fun a b -> a – b
// List.sortWith is a higher-order function, taking comparison function as an argument
numbers |> List.sortWith(ascending) // [1; 2; 3; 4; 7]
numbers |> List.sortWith(fun a b -> b - a) // [7; 4; 3; 2; 1]
let luminance color =
2126 * (int)color.R +
7152 * (int)color.G +
0722 * (int)color.B// Using data structures from previous example let colors = [green; yellow; red;] // Sort colors by luminance colors |> List.sortWith(fun c1 c2 -> luminance c1 - luminance c2) // [red; green; yellow]
And that’s not all, the availability of first-class functions has a number of crucial consequences that are described in the continuation of this article: The Pillars of Functional Programming (Part 2).

Nikolay is an advanced .NET developer working with Sigma Software for many years. He is passionate about technology and its progress, so Nikolay actively participates in tech community events, acts as a mentor and trainer, competes and takes high places at international Hackathons.


On November 27, in Lviv, Forbes AI Summit brought together entrepreneurs, technology leaders, and scientists for an honest conversation about how AI is reshapin...

The EU Data Act went live in September 2025. Its rollout across Europe has been uneven, with only a few member states having completed the national set-ups. Nev...

For years, manufacturers have been talking about the advantages of shifting to outcome-based business models. The rise of AI has made the opportunity for transf...